Publications
Group highlights
(For a full list of publications see below)
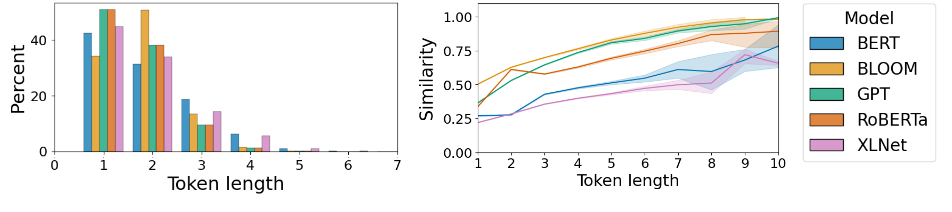
We show that semantic content accounts for less than 50% of most English contextual word embeddings even given 100 words of context.
J Matthews, J Starr, M van Schijndel
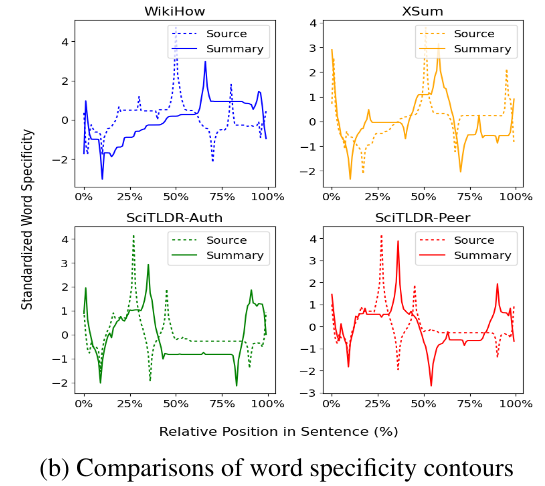
We study the linguistic compression function used by humans to generate single sentence summaries, and we examine the preference mismatches between summary writers and summary readers.
F Yin, M van Schijndel
Proc. Findings of EMNLP (2023)
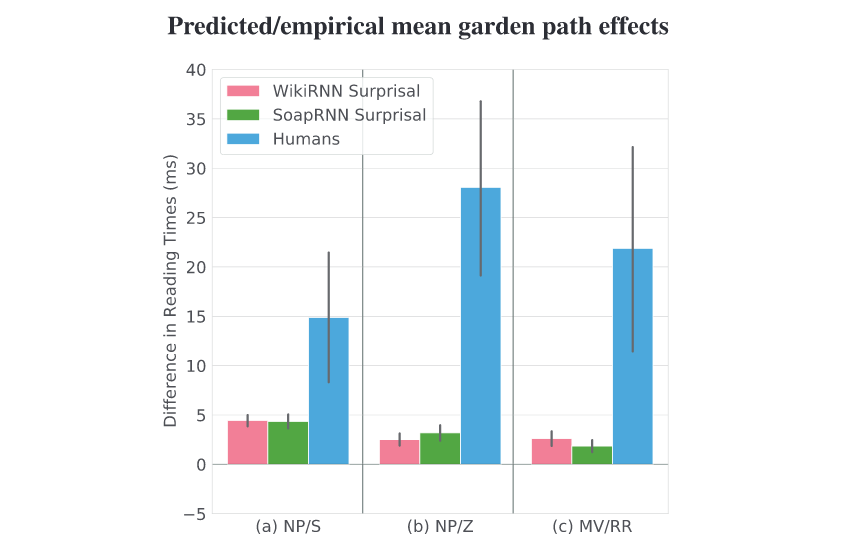
We show that surprisal (or more generally, single-stage prediction models) can only explain the existence of garden path effects in reading times, not the magnitude of the effects themselves. Suggests the existence of explicit repair mechanisms are involved during garden path processing.
M van Schijndel, T Linzen
Cognitive Science, 45 (6):e12988. (2021)
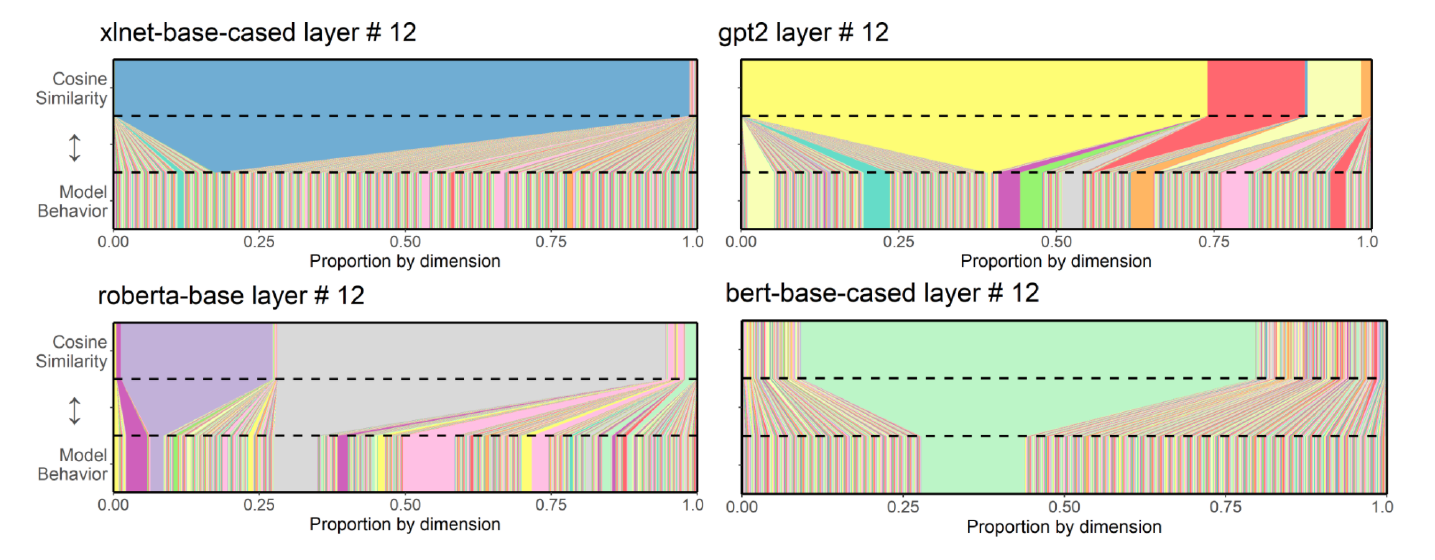
We show that Transformer models consistently develop rogue dimensions that operate at bizarrely inflated scales and track relatively uninteresting phenomena (e.g., time since last punctuation mark). The inflated scale distorts similarity estimates and makes cosine a poor measure of similarity. We introduce a very simple method to correct for the issue that retains all information in the model and requires no retraining.
W Timkey, M van Schijndel
Full List of publications
Semantics or Spelling? Probing contextual word embeddings with orthographic noise
J Matthews, J Starr, M van Schijndel
Proc. Findings ACL (2024)
Does Dependency Locality Predict Non-canonical Word Order in Hindi?
S Ranjan, M van Schijndel
Proc. Cogsci (2024)
Discourse Context Modulates Phonotactic Processing
J Starr, M van Schijndel
Proc. AMP (2023)
Linguistic Compression in Single-Sentence Human-Written Summaries
F Yin, M van Schijndel
Proc. Findings of EMNLP (2023)
Discourse Context Predictability Effects in Hindi Word Order
S Ranjan, M van Schijndel, S Agarwal, R Rajkumar
Proc. EMNLP (2022)
Dual Mechanism Priming Effects in Hindi Word Order
S Ranjan, M van Schijndel, S Agarwal, R Rajkumar
Proc. AACL (2022)
Single-stage prediction models do not explain the magnitude of syntactic disambiguation difficulty
M van Schijndel, T Linzen
Cognitive Science, 45 (6):e12988. (2021)
Finding Event Structure in Time: What Recurrent Neural Networks can tell us about Event Structure in Mind
F Davis, G T.M. Altmann
Cognition, 213:104651. (2021)
All Bark and No Bite: Rogue Dimensions in Transformer Language Models Obscure Representational Quality
W Timkey, M van Schijndel
Proc. EMNLP (2021)
Uncovering Constraint-Based Behavior in Neural Models via Targeted Fine-Tuning
F Davis, M van Schijndel
Proc. ACL-IJCNLP (2021)
To Point or Not to Point: Understanding How Abstractive Summarizers Paraphrase Text
M Wilber, W Timkey, M van Schijndel
Findings of ACL-IJCNLP (2021)
Analytical, Symbolic and First-Order Reasoning within Neural Architectures
S Ryb, M van Schijndel
Proc. CSTFRS (2021)
fMRI reveals language-specific predictive coding during naturalistic sentence comprehension
C Shain, I Blank, M van Schijndel, W Schuler, E Fedorenko
Neuropsychologia, 138:107307 (2020)
Discourse structure interacts with reference but not syntax in neural language models
F Davis, M van Schijndel
Proc. CoNLL (2020)
Filler-gaps that neural networks fail to generalize
D Bhattacharya, M van Schijndel
Proc. CoNLL (2020)
Interaction with context during recurrent neural network sentence processing
F Davis, M van Schijndel
Proc. CogSci (2020)
Recurrent Neural Network Language Models Always Learn English-Like Relative Clause Attachment
F Davis, M van Schijndel
Proc. ACL (2020)
Quantity doesn’t buy quality syntax with neural language models
M van Schijndel, A Mueller, T Linzen
Proc. EMNLP-IJCNLP (2019)
Using Priming to Uncover the Organization of Syntactic Representations in Neural Language Models
G Prasad, M van Schijndel, T Linzen
Proc. CoNLL (2019)
Can Entropy Explain Successor Surprisal Effects in Reading?
M van Schijndel, T Linzen
Proc. SCiL (2019)